4.1. Algorithm concepts¶
This page details the concepts used in vantage6 algorithms. Understanding these concepts is helpful when you to create your own algorithms. A guide to develop your own algorithms can be found in the Algorithm development step-by-step guide.
Algorithms are executed at the vantage6 node. The node receives a computation task from the vantage6 HQ. The node will then retrieve the algorithm, execute it and return the results to HQ.
Algorithms are shared using Docker images which are stored in a Docker image registry. The node downloads the algorithms from the Docker registry. In the following sections we explain the fundamentals of algorithm containers.
Algorithm structure: The typical structure of an algorithm
Input & output: Interface between the node and algorithm container
Wrappers: Library to simplify and standardized the node-algorithm input and output
Child containers: Creating subtasks from an algorithm container
Networking: Communicate with other algorithm containers and the vantage6 HQ
Cross language: Communicate across languages with data serialization
4.1.1. Algorithm structure¶
Multi-party analyses commonly have a central part and a remote part. The remote part is responsible for the actual analysis and the central part is often responsible for aggregating the partial results of the remote parts. An alternative to aggregating is orchestration, where the central part does not combine the partial results itself, but instead orchestrates the remote parts in a certain way that also leads to a global result. Of course, the central part may also do both aggregation and orchestration.
In vantage6, we refer to the orchestration part as the central function and the remote part as the partial function or federated function.
A common pattern for a central function would be:
Start remote tasks for the partial models from all participants
Wait for the remote tasks to complete and obtain the partial models
Combine the partial models to a global model
For iterative algorithms, step 1-3 can be repeated in a single central function until the model converges.
In vantage6, it is also possible to run only the partial parts of the analysis on the nodes and combine them on your own machine, but it is usually preferable to run the central part within vantage6, because then you don’t have to keep your machine running during the analysis, you do not need to run the central part yourself, and the results are stored on the HQ, so they may also be accessed by other users.
Note
Central functions also run at a node and not at HQ. For more information, see here.
4.1.2. Input & output¶
The algorithm runs in an isolated environment at the data station. It is important to limit the connectivity and accessability of an algorithm run for security reasons. For instance, by default, algorithms cannot access the internet, which would prevent any malicious algorithms from sending data over the internet.
In order for the algorithm to do its work, it is provided with several environment variables and file mounts. These file mounts are provided by the vantage6 infrastructure, so the algorithm developer does not need to provide these files themselves.
The available file mounts are:
- Input
The input file contains the user defined input. Usually, this consists of the algorithm method that should be called together with its arguments. The user specifies this when a task is created.
- Output
The algorithm writes its output to this file. When the docker container exits, the contents of this file will be sent back to the vantage6 HQ.
The file mounts are mapped to environment variables that are described in the Environment variables section.
4.1.3. Wrappers¶
The vantage6 algorithm wrappers simplify and standardize the interaction between algorithm and node. The algorithm wrapper does the following:
Supply the appropriate environment variables and file mounts to your algorithm.
Select the appropriate algorithm function to run and call it with the appropriate arguments.
Write the output of your algorithm function to the output file
The wrapper is language specific and currently only supports Python. Extending this to other languages should however be straightforward.
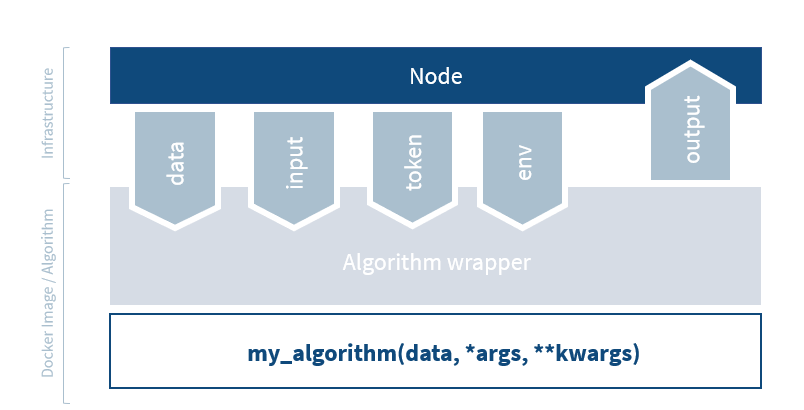
Fig. 4.1 The algorithm wrapper handles algorithm input and output.¶
4.1.4. Child containers¶
When a user creates a task, one or more nodes spawn an algorithm container. These algorithm containers can create new tasks themselves.
Only central functions are supplied with a JWT token (see Input & output).
This token can be used to communicate with the vantage6 HQ. In case
you use an algorithm wrapper, you can supply an AlgorithmClient using
the appropriate decorator.
A child container can be a parent container itself. There is no limit to the amount of task layers that can be created, but this is exceedingly rare. It is common to have only a single parent container which handles multiple child containers.
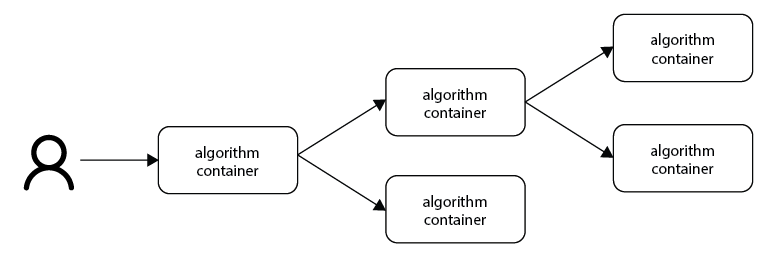
Fig. 4.2 Each container can spawn new containers in the network. Only central function containers are provided with a unique token which they can use to communicate to the vantage6 HQ.¶
The token to which the central function containers have access supplies limited permissions to the container. For example, the token can only be used to create child tasks in the same collaboration.
4.1.5. Networking¶
The algorithm containers are deployed in an isolated network to reduce their
exposure. Hence, by default, the algorithm containers cannot reach the internet. The
main exception is that
the vantage6 HQ is reachable through a local proxy service. In the algorithm you can use
the HOST, POST and API_PATH to find the address of the HQ.
Algorithm containers can be granted access to the internet by whitelisting addresses and domains in your node configuration. This can for instance be used to allow the algorithm to reach a database in the local network. This feature should be used with caution - whitelisting unsafe addresses and domains can expose your data to attacks.
4.1.6. Cross language¶
Because algorithms are run as Docker images they can be written in any programming language. This is an advantage as developers can use their preferred language for the problem they need to solve.
Warning
The wrappers are only available for Python, so when you use different language you need to handle the IO yourself. Consult the Input & Output section on what the node supplies to your algorithm container.
When data is exchanged between the user and the algorithm they both need
to be able to read the data. When the algorithm uses a language specific
serialization (e.g. a pickle in the case of Python or RData in
the case of R) the user needs to use the same language to read the
results. Therefore, we recommend using a type of serialization that
is not specific to a language. In the vantage6 infrastructure wrappers, JSON is used.
Note
Communication between algorithm containers can use language specific serialization as long as the different parts of the algorithm use the same language.