Introduction¶
In many research projects, data is distributed across multiple organizations. This makes it difficult to perform analyses that require data from multiple sources, as the data owners don’t want to share their data with others. Vantage6 is a platform that enables privacy-enhancing analyses on distributed data. It allows organizations to collaborate on analyses while only sharing aggregated results, not the raw data.
As a user, you can use vantage6 to run your algorithms on sensitive data. In order to create the tasks to run your algorithms, you need to understand how vantage6 works. We will first explain the basic architecture of vantage6, followed by a description of the resources available in vantage6. Using those concepts, we will explain give an example of a simple algorithm and explain how it is run within vantage6.
Vantage6 components¶
In vantage6, a client can pose a question to the headquarters (HQ). The headquarters knows which organizations work together in a network. Each organization contributes one node to the network that may contain sensitive data. HQ alerts the nodes of new questions. Nodes then fetch algorithms to answer the question. When the algorithm completes, the node sends the non-sensitive, aggregated results back to HQ.

The roles of these vantage6 components are as follows:
Headquarters coordinates communication with clients and nodes. HQ tracks the status of the computation requests, stores the results, and keeps track of who is allowed to do what.
Node(s) have access to data and execute algorithms
Clients (i.e. users or applications) request computations from the nodes via the client
Algorithms are scripts that are run on the sensitive data. Each algorithm is packaged in a container image; the node pulls the image from a container registry and runs it on the local data. Note that the node owner can control which algorithms are allowed to run on their data.
Headquarters is part of the vantage6 hub, which is the collection of all central components of the vantage6 infrastructure. Apart from HQ, the hub contains the following important components:
Authentication service: The authentication service for the vantage6 network.
Algorithm store: A place to share vantage6 algorithms (optional).
User interface: A web interface to use vantage6 (optional).
In addition, the hub can also spin up more services, such as message brokers, databases, and monitoring services, if the configuration specifies so.
On a technical level, vantage6 may be seen as a container orchestration tool for privacy-preserving analyses. It deploys a network of containerized applications that together ensure insights can be exchanged without sharing record-level data.
Vantage6 resources¶
There are several entities in vantage6, such as users, organizations, tasks, etc. These entities are created by users that have sufficient permission to do so and are stored in a database that is managed by HQ. This process ensures that the right people have the right access to the right actions, and that organizations can only collaborate with each other if they agree to do so.
The following statements and the figure below should help you understand their relationships.
A collaboration is a collection of one or more organizations.
For each collaboration, each participating organization needs a node to compute tasks. When a collaboration is created, accounts are also created for the nodes so that they can securely communicate with HQ.
Collaborations can contain studies. A study is a subset of organizations from the collaboration that are involved in a specific research question. By setting up studies, it can be easier to send tasks to a subset of the organizations in a collaboration and to keep track of the results of these analyses.
Each organization has zero or more users.
The permissions of the user are defined by the assigned rules.
It is possible to collect multiple rules into a role, which can also be assigned to a user.
Each collaboration can contain multiple sessions in which data may be analysed. A session can contain multiple dataframes. A dataframe is a collection of data retrieved from the original source database that is stored on the node. A dataframe can be modified by additional user defined preprocessing steps and can be used as input for tasks.
Users can create tasks for one or more organizations within a collaboration and session. Tasks lead to the execution of the algorithms.
A task should produce an algorithm run for each organization involved in the task. The results are part of such an algorithm run.
The following schema is a simplified version of the database. The 1-n, 0-n and n-n relationships describe one-to-many, zero-to-many and many-to-many relationships, respectively.

A simple federated average algorithm¶
To compute an average, you usually sum all the values and divide them by the number of values. In Python, this can be done as follows:
x = [1,2,3,4,5]
average = sum(x) / len(x)
In a federated data set the values for x are distributed over multiple locations. Let’s assume x is split into two parties:
a = [1,2,3]
b = [4,5]
In this case we can compute the average as:
average = (sum(a) + sum(b))/(len(a) + len(b))
The goal is to compute the average without sharing the individual numbers. In the case of an average algorithm, each node therefore shares only the sum and the number of elements in the dataset. By summing the sums and dividing by the sum of the number of elements, the average can be found. This way, the individual numbers are never shared:
# on node 1
a = [1,2,3]
return {"sum": sum(a), "count": len(a)}
# on node 2
b = [4,5]
return {"sum": sum(b), "count": len(b)}
# computing the average of both nodes
average = (node_1["sum"] + node_2["sum"]) / (node_1["count"] + node_2["count"])
How algorithms work in vantage6¶
The average algorithm explained above can be separated in a central part and a federated part. The federated part uses the data to compute the sum and the number of elements. The central part is the aggregation of these results. In order to do so, it is also responsible to start the federated parts and to collecting their results. Note that for more complex algorithms, this can be an iterative process: the central part can send new tasks to the federated parts based on the results of the previous round of federated tasks.
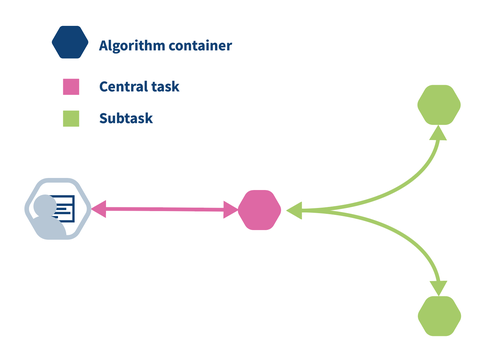
Fig. 1 Common task hierarchy in vantage6. The user (left) creates a task for the central part of the algorithm (pink hexagon). The central part creates subtasks for the federated parts (green hexagons). When the subtasks are finished, the central part collects the results and computes the final result, which is then available to the user.¶
Now, let’s see how this works in vantage6. It is easy to confuse HQ with the central part of the algorithm: HQ is the central part of the infrastructure but not the place where the central part of the algorithm is executed (Fig. 2). The central part is actually executed at one of the nodes, because it gives more flexibility: for instance, an algorithm may need heavy compute resources to do the aggregation, and it is better to do this at a node that has these resources rather than having to upgrade HQ’s resources whenever a new algorithm needs more resources.
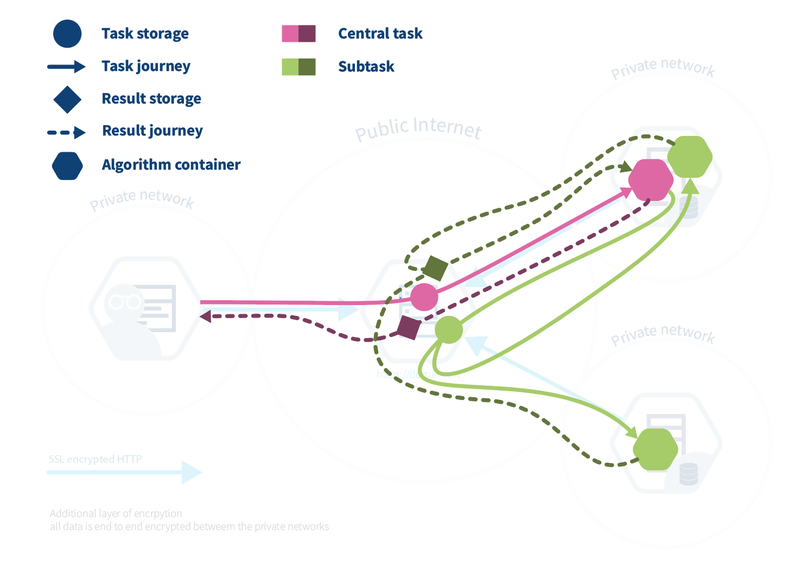
Fig. 2 The flow of the average algorithm in vantage6. The user creates a task for the central part of the algorithm. This is registered at HQ, and leads to the creation of a central algorithm container on one of the nodes. The central algorithm then creates subtasks for the federated parts of the algorithm, which again are registered at HQ. All nodes for which the subtask is intended start their work by executing the federated part of the algorithm. The nodes send the results back to HQ, from where they are picked up by the central algorithm. The central algorithm then computes the final result and sends it to HQ, where the user can retrieve it.¶
Note
It is also possible for the user to create the subtasks directly, and to compute the central part of the algorithm themselves. However, this is not the most common approach as it is generally easier to let the central algorithm do the work.
How to run algorithms in vantage6¶
Once you have set up a vantage6 hub and nodes, you are ready to run your algorithms. You can create tasks from the web interface, the Python client or by interacting with the API directly. There are a number of public algorithms available from the community algorithm store. Linking this store to your HQ will allow you to quickly get a set of algorithms that you can run on your nodes.
You can also develop your own vantage6 algorithms. The only requirement is that you package the algorithm in a container image that vantage6 can run. The focus of vantage6 is on setting up an infrastructure to run algorithms on sensitive data and ensuring that the data is kept private - the algorithm implementation is kept highly flexible.
The freedom in defining the code also allows you to use federated learning libraries such as PySyft, TensorFlow or Flower within your vantage6 algorithm. Also, it is not only possible to run federated algorithms, but also MPC algorithms or other protocols.
Note
Vantage6 tries to limit the definition of algorithms as little as possible. This means that within a project, it should be established which algorithms are allowed to run on the nodes. Review of this code - or trust in persons that have created the algorithm - is the responsibility of each node owner. They are ultimately in control over which algorithms are run on their data.
Vantage6 is designed to be as flexible as possible, so you can use any programming language and any libraries you like. Python is the most common language to use within the vantage6 community, and also has the most tools available to help you with algorithm development.