5.1. Architecture#
5.1.1. Network Actors#
Server#
Note
When we refer to the server, this is not just the vantage6-server, but also other infrastructure components that the vantage6 server relies on.
The server is responsible for coordinating all communication in the vantage6 network. It consists of several components:
- vantage6 server
Contains the users, organizations, collaborations, tasks and their results. It handles authentication and authorization to the system and is the central point of contact for clients and nodes. For more details see vantage6-server.
- Docker registry
Contains algorithms stored in Images which can be used by clients to request a computation. The node will retrieve the algorithm from this registry and execute it. It is possible to use Docker hub for this, however some (minor) features will not work.
An optional additional feature of the Docker registry would be Docker Notary. This is a service allows verification of the algorithm author.
- VPN server (optionally)
Is required if algorithms need to be able to engage in peer-to-peer communication. This is usually the case when working with MPC but can also be useful for other use cases.
- RabbitMQ message queue (optionally)
The vantage6-server uses the web-sockets protocol to communicate between server, nodes and clients it is impossible to horizontally scale the number of vantage6-server instances. RabbitMQ is used to synchronize the messages between multiple vantage6-server instances.
Data Station#
- vantage6-node
The data station hosts the node (vantage6-node) and a database. The database could be in any format, but not all algorithms support all database types. There is tooling available for CSV, Parquet and SPARQL. There are other data-adapters (e.g. OMOP and FHIR) in development. For more details see vantage6-node.
- database
The node is responsible for executing the algorithms on the local data. It protects the data by allowing only specified algorithms to be executed after verifying their origin. The vantage6-node is responsible for picking up the task, executing the algorithm and sending the results back to the server. The node needs access to local data. This data can either be a file (e.g. csv) or a service (e.g. a database).
User or Application#
A user or application interacts with the vantage6-server. They can create tasks and retrieve their results, or manage entities at the server (i.e. creating or editing users, organizations and collaborations). This can be done using clients or the user-interface. For more details see vantage6-clients and vantage6-UI.
5.1.2. Components#
vantage6-server#
vantage6-node#
vantage6-clients#
vantage6-UI#
Implementation details are given in the /node/node, /server/server, and /api sections of the documentation.
Note
The following sections are based on our publications:
5.1.3. Architecture#
Vantage6 uses a client-server model, which is shown in
architecture-overview. In this scenario, the researcher can pose a
question and using his/her preferred programming language, send it as a task
(also known as computation request) to the (central) server through function
calls. The server is in charge of processing the task as well as of handling
administrative functions such as authentication and authorization. The
requested algorithm is delivered as a container image to the nodes, which have
access to their own (local) data. When the algorithm has reached a solution,
it is transmitted via the server to the researcher. A more detailed
explanation of these components is given as follows.
First, the researcher defines a question. In order to answer it, (s)he identifies which parties possess the required data and establishes a collaboration with them. Then, the parties specify which variables are needed and, more importantly, they agree on their definition. Preferably, this is done following previously established data standards suitable for the field and question at hand. Moreover, it is strongly encouraged that the parties adhere to practices and principles that make their data FAIR (findable, accessible, interoperable, and reusable).
Once this is done, the researcher can pose his/her question as a task to the server in an HTTP request. Vantage6 allows the researcher to do so using any platform of his/her preference (e.g., Python, R, Postman, custom UI, etc.). The request contains a JSON body which includes information about the collaboration and the party for which the request is intended, a reference to a Docker image (corresponding to the selected algorithm), and optional inputs (usually algorithm parameters). By default, the task is sent to all parties.
Vantage6’s processing of the task (i.e., server and nodes functionality) occurs behind the scenes. The researcher only needs to deal with his/her working environment (e.g., Jupyter notebook, RStudio).
Once the results are ready, the researcher can obtain them in two ways: on demand (i.e., polling), or through a continuous connection with the server where messages can be sent/received instantly (i.e., WebSocket channel). Due to its speed and efficiency, the latter is preferred.
Fig. 5.1 shows a more detailed diagram of vantage6’s server. First, the server is configured by an administrator through a command line interface. The server’s parameters (e.g., IP, port, log settings, etc.) are stored into a configuration file. The latter is loaded when the server starts. Once the server is running, entities (e.g., tasks, users, nodes) can be managed through a RESTful API. Furthermore, a WebSocket channel allows communication of simple messages (e.g., status updates) between the different components. This reduces the number of server requests (i.e., neither the researcher nor the nodes need to poll for tasks or results), improving the speed and efficiency of message transmission.
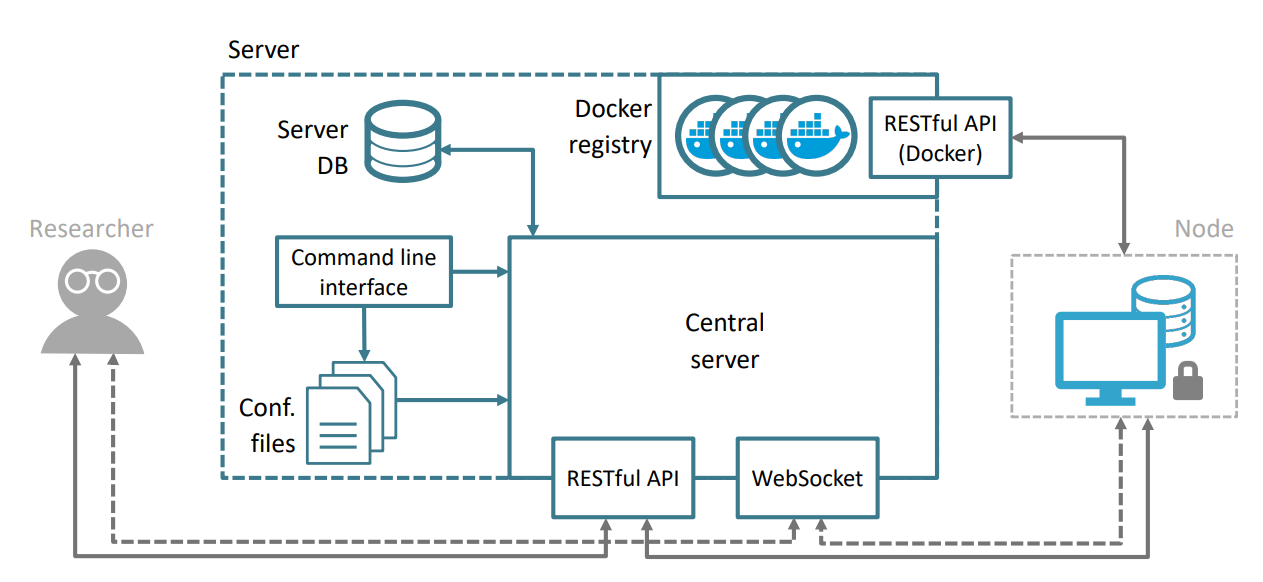
Fig. 5.1 Vantage6’s server. An administrator uses the command line interface to configure and start the server. After the server loads its configuration parameters (which are stored in a YAML file), it exposes its RESTful API. It is worth noting that the central server’s RESTful API is different from that of the Docker registry.#
The central server also stores metadata and information of the researcher (user), parties, collaborations, tasks, nodes, and results. Fig. 5.2 shows its corresponding database model.
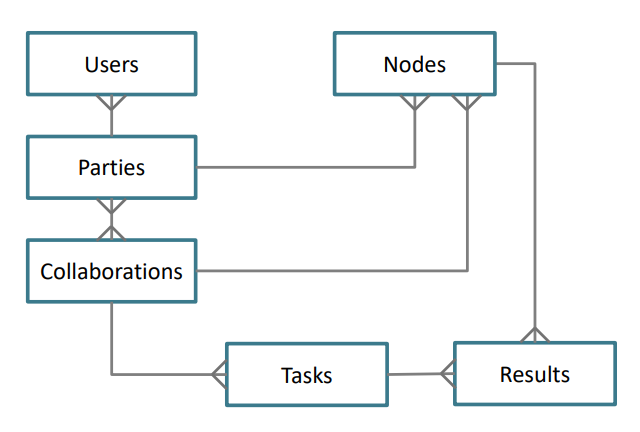
Fig. 5.2 Database model of the central server (Fig. 5.1). The users are always members of a party, which can participate in multiple collaborations. Within a party, users can have different roles (e.g., an administrator is allowed to accept collaborations). For each collaboration a party takes place in, it should create a (running) node. Tasks are always part of a single collaboration and have one or multiple results. In turn, results are always part of a single task and node.#
A single computation request can lead to many requests to the server, especially when an iterative algorithm is used in combination with many nodes (Assuming the algorithm does not make heavily use of the direct-communication feature). Therefore it is important that the server can handle multiple requests at once. To achief this, the server needs to be able to scale horizontally.
The server and node have a peristent connection through a websocket channel. This complicates the horizontal scalability as nodes can connect to different server instances. E.g. it is not trivial to send a message to all parties when an event occurs in one of the server instances. This problem can be solved by introducing a message broken to which all server instances connect to synchronise all messages.
Algorithm containers can directly communicate (using a ip/port combination) with other algorithm containers in the network using a VPN service. This VPN service needs to be configured in the server as the nodes automatically retrieve the VPN certificates on startup (when the VPN option enabled).
In order for the vantage6-server to retrieve the certificates from the VPN server, this VPN server required to have an API to do so. Therefore the open-source EduVPN solution is used. Which is basically a wrapper arround an OpenVPN instance to provide a feature rich interface.
In order to host a node, the parties need to comply with a few minimal system requirements: Python 3.6+, Docker Community Edition (CE), a stable internet connection, and access to the data. Figure 5 shows a more detailed diagram of a single VANTAGE6 node.
In this case, an administrator uses a command line interface to configure the node’s core and to start the Docker daemon. We can think of the latter as a service which manages Docker images, containers, volumes, etc. The daemon starts the node’s core, which in turn instructs the daemon to create the data volume. The latter contains a copy of the host’s data of interest. It is in this moment when the party can exert its autonomy by deciding how much of its data will it allow to contribute to the global solution at hand. After this step, all the pieces are in place for the task execution.
The node receives a task from the server (which could involve a master or an algorithm container) and executes it by downloading the requested (and previously approved) Docker image. The corresponding container accesses the local data through the node and executes the algorithm with the given parameters. Then, the algorithm outputs a set of (intermediate) results, which is sent to the server through the RESTful API. The user or the master container collects these results of all nodes. If needed, it computes a first version of the global solution and sends it back to the nodes, which use it to compute a new set of results. This process could be iteratively until the model’s global solution converges or after a fixed number of iterations. This iterative approach is quite generic and allows flexibility by supporting numerous algorithms that deal with horizontally- or vertically-partitioned data.
It is worth emphasizing that the data always stay at their original location It is only intermediate results (i.e., aggregated values, coefficients) that are transmitted, which immensely reduce the risk of leaking private patient information. Furthermore, all messages (node to node, node to user) are end-to-end-encrypted, adding an extra layer of security. It is also worth mentioning that the parties hosting the nodes are allowed to be heterogeneous: as long as they comply with the minimal system requirements, they can have their own hardware and operating system.